Decision Tree From Scratch¶
Overview
In this section, we walk-through building a Risk Based Prioritization Decision Tree for use as a first-pass triage of CVEs based on Prioritizing Vulnerability Response: A Stakeholder-Specific Vulnerability Categorization (Version 2.0) from scratch, in code.
The recipe:
- Build a Decision Tree from scratch
- Find the Decisions (Prioritization) for some vulnerabilities with CVEs
- Visualize the flow / distribution of vulnerabilities across our Decision Tree branches

Why Decision Trees?¶
- Focus on what matters: risk and its constituent factors and what action needs to be taken when.
- Understandable.
- Modular: e.g. allows change/customization of Mission & Well-being Decision Node for an organization. Loose coupling, high cohesion.
- Decision Tree Analysis can be applied (see source code).
- Trees give a very clear visual of all the parameters and decision nodes e.g. Attack Trees for Threat Modelling. Formulas are opaque, single output.
Overview¶
Risk is per Asset and depends on Impact of a Vulnerability being exploited by a Threat per NIST Special Publication 800-30 r1 Guide for Conducting Risk Assessments.
One approach to assess risk is to do multiple passes - starting with a first pass triage of vulnerabilities
- First pass: Prioritize Vulnerabilities in an automated way
independent of Asset
- Given a list of vulnerabilities, prioritize them given what we know about the vulnerability from multiple data sources (independent of the assets i.e. assume a generic asset for risk purposes for this first pass).
- Second pass: Dependent on Asset
- There can be MANY independent parameters that determine the risk
associated with an Asset e.g.
- Value
- Exposure e.g. open (to the internet)
- Reachability - is the vulnerable method called
- Compensating controls
- Underlying Stack component versions in place e.g. SpringShell Spring Framework exploitability depends on certain JDK versions.
- Many of these parameters are generic for the vulnerabilities associated with the Asset - and are known in advance and fixed e.g. Asset Value, Asset Exposure.
- There can be MANY independent parameters that determine the risk
associated with an Asset e.g.
- Some of the parameters will depend on the specific vulnerability and the pre-conditions it needs to implement the full kill-chain. E.g. exploitable depending on the configuration or runtime context of the vulnerable software.
This 2 pass approach allows us to first determine the highest priority vulnerabilities - and then assess these against our highest value/exposure assets.
We’ll walk through this First Pass triage - using a Decision Tree to prioritize the vulnerabilities.
- We’ll build this Decision Tree from scratch.
- An extract of the data is shown for each step. So we can see what’s happening without needing to understand the code
- A key benefit to Decision Trees is that they are understandable. The implementation of them should support that too. So the code here aims for clarity e.g. laid out inline.
Decision Tree Node Inputs¶

The data sources used
- Exploitation
- Active Exploitation: CISA KEV
- Commercial CTI data on what CVEs are actively exploited, was not used in this example because all of the data and source is provided for the example.
- Weaponized Exploits: Metasploit, Nuclei
- Likelihood of exploit using EPSS above a threshold
- Active Exploitation: CISA KEV
- Automatable
- Using CVSS Base Metric Exploitability parameters (not the score itself)
- Impact
- Using CVSS Base Metric Impact parameters (not the score itself)
- The Impact parameters Confidentiality, Integrity do not
offer much granularity as discussed in CVSS section.
- These could be replaced with other impacts if available e.g. "Remote Code Execution", "Denial of Service", "Arbitrary File Read", "Arbitrary File Write",...
- The Impact parameters Confidentiality, Integrity do not
offer much granularity as discussed in CVSS section.
- Using CVSS Base Metric Impact parameters (not the score itself)
This Exploitation Decision data can be used for any risk prioritization scheme
This Exploitation Decision data can be used for any risk prioritization scheme i.e. not specific to SSVC.
- It could be used to inform CVSS Exploit Maturity (E)
A venn diagram of these 3 Decision Nodes for all CVSS v3 CVEs shows that "Exploitation Active" is a relatively small subset compared to "Automatable - Yes" and "Technical Impact - Total".
This reinforces the guidance to "prioritize vulnerabilities that are being exploited in the wild or are likely to be"

Decision Tree Output¶

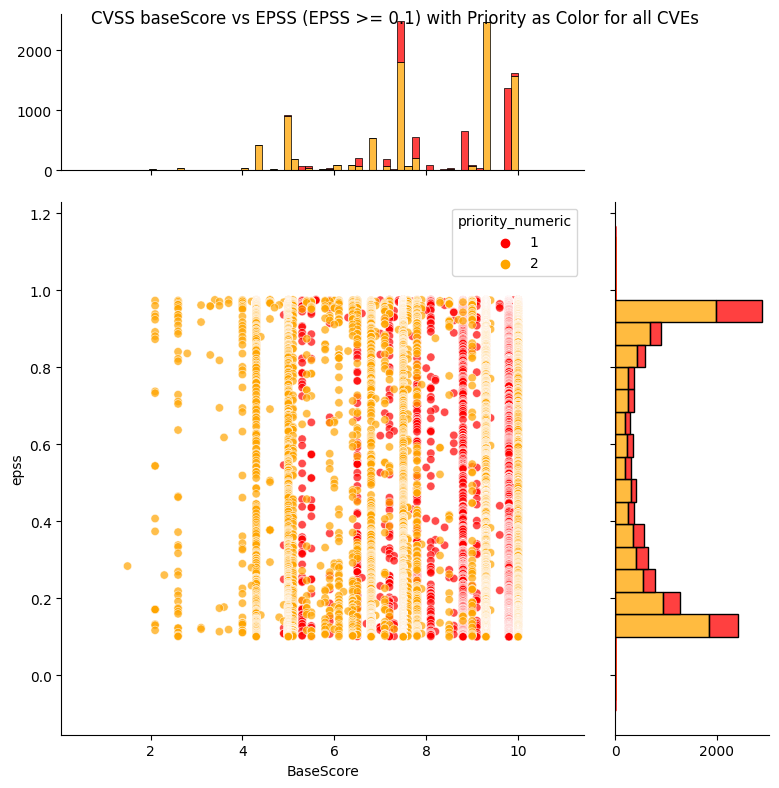
Observations
- The low priority "Track*", "Track" CVEs are spread across the CVSS Base score, but have low EPSS scores.
- Most CVEs have low EPSS scores i.e. the histogram on the right shows a large count near zero EPSS score.
- The most common CVSS scores are around 7.5 and 9.8 (per histogram on top).
- The top priority "Act", "Attend" CVEs are spread across the CVSS Base score, and EPSS scores.
CVEs across the Decision Tree¶
A different way to visualize the Decisions across CVEs is to use a sankey diagram to show how CVEs flow through the tree Decision Nodes
- running the source code provided gives an interactive version of the plot

The vertical size of the band represents the count of CVEs
The color represents the risk e.g. red is high risk.
Observations
- There's a relatively small subset of CVEs that have
- Exploitation - Active
- Automatable - Yes
- Technical Impact - Total
- This fine granularity and clarity is in stark contrast to the coarse granularity of CVSS ratings.
- The count of CVEs for the highest Decision/Priority is relatively low, and the counts increase as the Decision/Priority decreases i.e. this is very desirable when we want to remediate by highest priority first!
Triage CVEs by Priority¶
The source code includes a selected list of CVEs to show how easy it is to apply the Decision Tree to a list of CVEs.
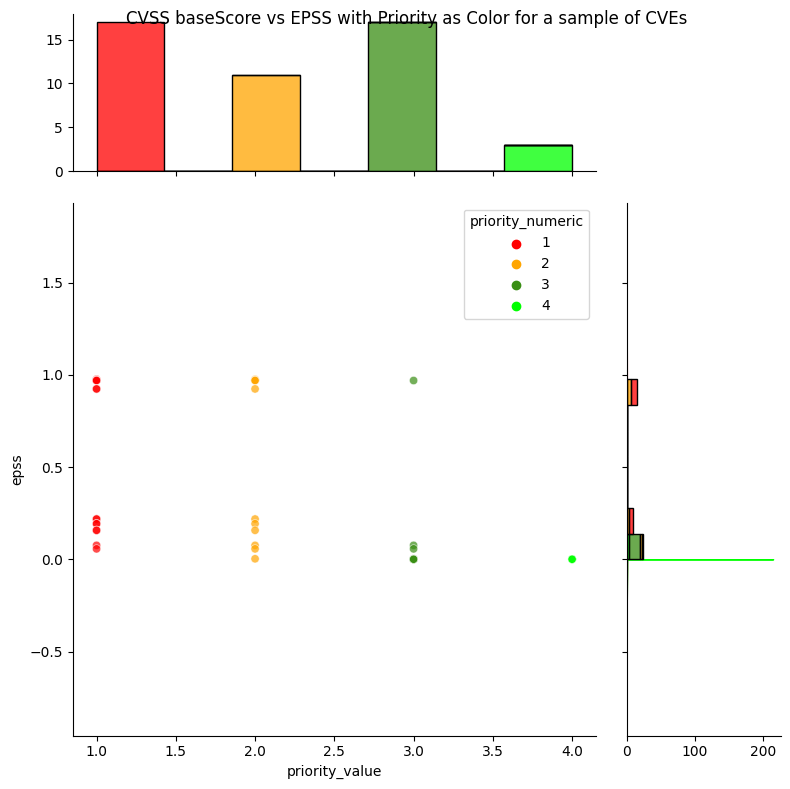
Observations
We get
- Static decisions / priority: (1:Act, 2:Attend, 3:Track Closely, 4:Track)
- Temporal likelihood of exploitation via EPSS, where EPSS scores can change depend on observed exploitation activity
- A way to prioritize per decision / priority e.g. For CVEs with "Act" decision, prioritize based on EPSS score.
Takeaways
- The Decision Tree gives give an effective prioritization vs population (in stark contrast to the coarse granularity of CVSS score or ratings).
- Applying the Decision Trees to a list of CVEs is a simple 1 liner merge based on CVEs (see source code)
- We can get the best of both worlds with
- static priority decisions based on our Decision Tree output
- temporal EPSS score